
Bonjours!
Who wants to land on the moon? Perhaps guided by an artificial intelligent agent?
I’ll quickly go over using one of the easiest reinforcement learning libraries so you can train a Rocketship to land on the moon (or a moon). We’ll be training a deep learning model to play a game called lunar lander.
A primer on a primer on reinforcement learning
If you’re familiar with markov chains and deep learning then deep reinforcement learning is probably something you can grasp easily.
If not, imagine you can train someone with positive or negative reinforcement to complete a task that they have no clue how to achieve. Reinforcement learning is a branch of machine learning that trains an agent to execute a set of actions for rewards.
It’s like markov chains because you have a state and based on that state you might want to perform certain actions to maximise or minimise a reward function. The sequence of possible events depend only on the state attained in the previous event.
Some technical terminologies that I’ll be avoiding include
- Observation Space: Description of the state of the world
- Action Space: Description of the number of possible actions
- Reward functions: Like in machine learning you have an “error function” in reinforcement learning you have a reward function to maximise or a penalty function to minimise.
Getting started with Reinforcement Learning
If you’re familiar with scikit-learn for supervised and unsupervised machine learning then stable-baselines is a similar package for reinforcement learning.
It reminds me of the early days of sklearn when it had few algorithms. This reinforcement learning library has fewish algorithms but they are very effective.
To train a reinforcement learning model to play a game, you need a game environment, something to record it’s failures and successes in video and the need to choose an appropriate algorithm.
How to get everything working
Using Conda create a new environment, if you don’t know what I’m talking about have a look here first.
We need a python 3.7ish environment as of today to support all the packages we will be using.
conda create --name fpserl python=3.7 conda activate fpserl
My VSC throws a fit about needing ipykernel so we’ll install that to get .ipynb files working in VSC
Type this into your terminal
pip install ipykernel
The gYM
Thanks to OpenAI we can find games with predefined rules to test different models by installing what is called the gym. The gym is where you weight train your models.
Installing it without errors requires a specific version of pyglet.
pip install pyglet==1.5.1 conda install -c conda-forge swig pip install gym[box2d]
You’ll notice I used a mixture of pip and conda installs. Conda is a universal package manager and can install other packages too. For example I installed the language R with conda. We’ll need a combination of non-python and python packages. The non-python ones I chose to install with conda, however feel free to apt-get if that is your preference. For the python packages I use pip.

The sklearn for Reinforcement Learning
Finally, we’ll need stable-baselines, one of the dependencies is gym but since gym needed a few additional steps to get working (at least for me) I have it separately in the above section.
This is how you should install sb3.
pip install stable-baselines3[extra]
Lastly you need ipywidgets if like me you use VSC. Otherwise you get an error like this eventually:

pip install ipywidgets
Cool! Now we should have everything to move on to the fun part.
Making a bot land a rocket on the moon
Nice work! Now we can create an ipynb file and import all the things we installed.
import gym from stable_baselines3 import PPO from stable_baselines3.common.evaluation import evaluate_policy from stable_baselines3.common.env_util import make_vec_env

We can create the lunar lander environment by simply running this command.
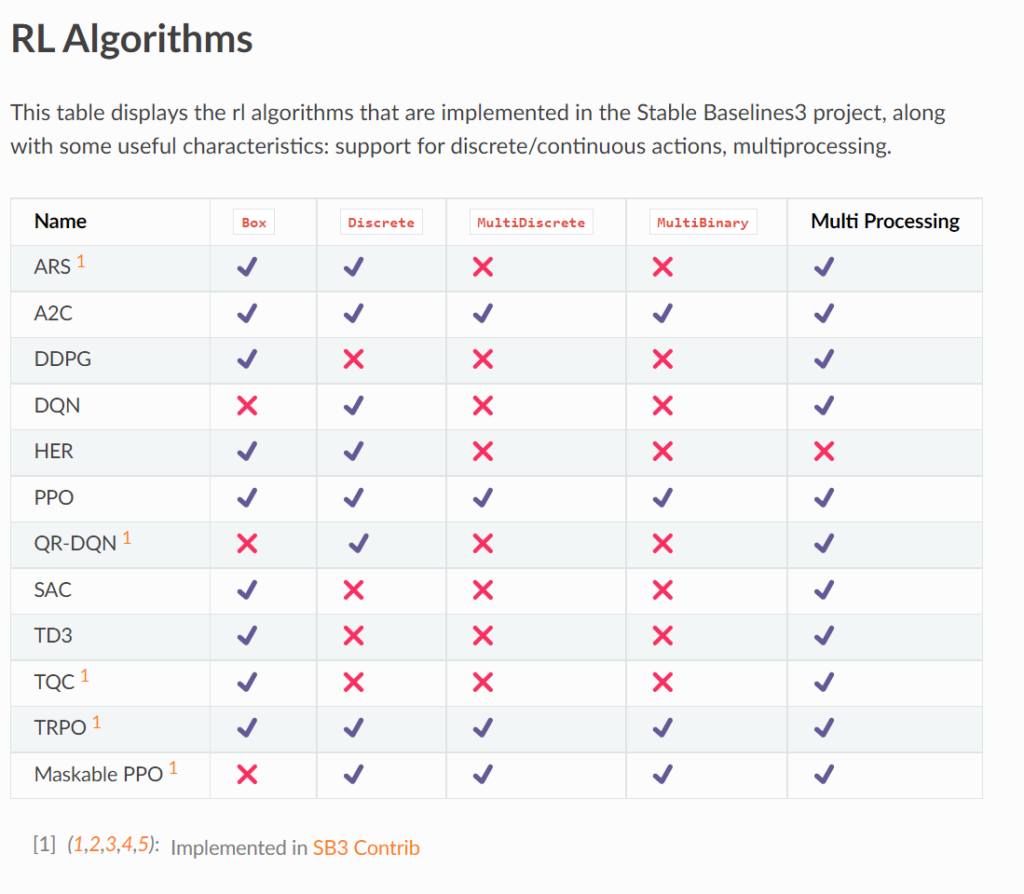
env = gym.make("LunarLander-v2")Now pick a model, I picked PPO because it had all the tick marks in the RL algorithms page. Proximal Policy Optimisation is one of the best performing algorithms in reinforcement learning right now.

You can find more information about the algorithm here
https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html
model = PPO(
policy = 'MlpPolicy',
env = env,
n_steps = 1024,
batch_size = 64,
n_epochs = 2,
gamma = 0.999,
gae_lambda = 0.98,
ent_coef = 0.01,
verbose=1,
device="cpu") #can be gpu but I had to install cuda for thatYou don’t have to define all the parameters I defined above, I did so to make training quicker.
Training and Testing
Wellp since you have that sorted you train and test just like you do in sklearn. The higher the timesteps the better it’ll perform in the given environment.
model.learn(total_timesteps=500000)
I trained my model for 2 million timesteps. I have a different philosophy when it comes to RL agents that play games. Unlike the usual regression and classification problems where you want the model to be quite generalisable, I think RL models can be trained extensively because you’re only making them play the same game.
Overfitting is less of a problem unless you want to train in a particular game/gym and use it elsewhere in a different environment. Let it train for whatever timesteps you’re willing to wait for and don’t worry about overfitting. There are a bunch of tweets that said the same from a bunch of popular people in RL that train state of the art models. I believe everything on twitter.
The best part about using an existing gym is that you don’t have to specify the reward and actions the model can use. The lunar lander game already comes with a reward function. I’ll make another blog post about using Unity to make your own gym eventually.
Unless you’re using a potato to train your model and still waiting please evaluate the model like so
eval_env = gym.make("LunarLander-v2")
mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=10, deterministic=True)
print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
It’s also a good idea to save the model
model.save('moonlanding')You can load it when you want it without having to retrain it.
model = PPO.load('moonlanding')Watch your beautiful agent winning.
episodes = 5
for ep in range(episodes):
obs = env.reset()
done = False
while not done:
action, _states = model.predict(obs)
obs, rewards, done, info = env.step(action)
env.render()
print(rewards)If you have problems with your kernel crashing and you have to keep restarting your notebook try this to avoid running everything again.
import gym
from stable_baselines3 import PPO
from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3.common.env_util import make_vec_env
episodes = 5
def play_f_model(episodes = episodes):
env = gym.make("LunarLander-v2")
model = PPO.load('moonlanding')
for ep in range(episodes):
obs = env.reset()
done = False
while not done:
action, _states = model.predict(obs)
obs, rewards, done, info = env.step(action)
env.render()
print(rewards)
play_f_model()
Congrats! You trained your first reinforcement learning model to play a game better than or equal to humans.
Things you can try
- How to come up with your own reward functions
- Trying out different gym environments
- Optimising the hyperparameters in the model
- Using different models but you’ll find PPO works for most cases
Ref
- https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html
- https://arxiv.org/abs/1901.08128