

Shalom,
We’ll keep it simple. It’s hard to be a small business that cant get any visibility. You are essentially competing against big companies with hoards of SEO experts, digital marketers, copywriters, graphic designers etc.
This is going to be a quick way for you to compete and hopefully rank first on the Goog.
We will grab people’s website structure, get the article links, generate our own article and cover image then upload it automatically to your CMS.
The steps to AI your way to victory
Open up your Python notebook like the winner you are. Feel free to use Colab if you need.
Find the XML sitemap.
I suppose we better make a folder to hold hundreds of xml files.
#Pick directory to save the sitemap
import os
download_folder = 'sitemaps' # Replace with the path to your desired folder
if not os.path.exists(download_folder):
os.makedirs(download_folder)We need to find the sitemap url. There are two ways to do it. Most websites just have it as website.com/sitemap.xml. Some have slightly different names for them but their location is usually in website.com/robot.txt
Lets make two functions. I’m partial to only checking /sitemap.xml because if people don’t want you to find it they usually change that url; so this is an ethical way of doing it, right?
# We need to find the sitemap URL
import requests
#Set the header, pretend to be googlebot (optional)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.4 Safari/605.1.15'
}
def find_sitemap_url(robots_url, headers):
"""Attempt to find the sitemap URL in the robots.txt file."""
try:
response = requests.get(robots_url, headers=headers)
response.raise_for_status() # Raises an HTTPError if the response was an error
for line in response.text.splitlines():
if line.startswith('Sitemap:'):
return [line.split(':', 1)[1].strip()]
except Exception as e:
print(f"Error fetching or parsing robots.txt: {e}")
return []
def try_common_sitemap_urls(base_url, headers):
"""Attempt to directly access common sitemap URLs."""
common_paths = ['/sitemap.xml', '/sitemap_index.xml', '/page-sitemap.xml', '/post-sitemap.xml', '/post-sitemap2.xml','/event-sitemap.xml','/news-sitemap.xml','/sitemap_index.xml','/prodcut-sitemap.xml','/prodcuts-sitemap.xml','/partners-sitemap.xml']
found_sitemaps = []
for path in common_paths:
url = base_url.rstrip('/') + path
try:
response = requests.head(url, headers=headers)
if response.status_code == 200:
found_sitemaps.append(url)
except Exception as e:
print(f"Error checking URL {url}: {e}")
return found_sitemapsCool, I used the second function on my own website. Sometimes places have many XML files. We don’t care – we can get them all.
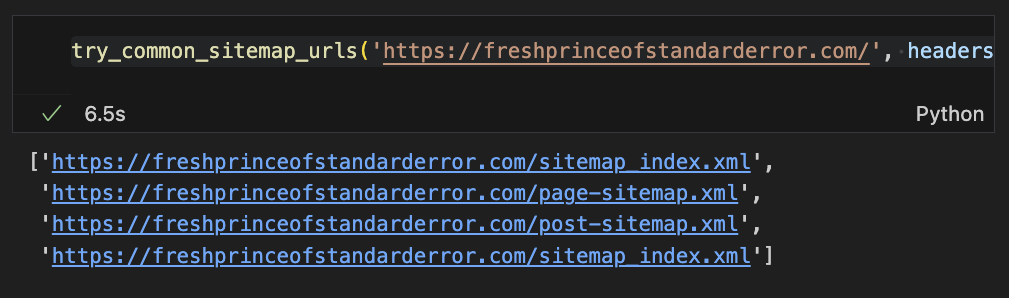
Download the XML sitemap
It’s simple. We’ll make sure the names make sense. Something like sitename_xmlfile.xml.
from urllib.parse import urlparse
def download_sitemap(url, headers, folder):
"""Download the sitemap content and save to the specified folder."""
response = requests.get(url, headers=headers)
response.raise_for_status() # Ensure we notice bad responses
# Use urlparse to get the domain and path to create a unique filename
url_parts = urlparse(url)
domain = url_parts.netloc.replace("www.", "") # Remove 'www.' if present
path = url_parts.path.lstrip('/').replace('/', '_') # Replace slashes with underscores
filename = f"{domain}_{path}" if path else domain # Construct filename using domain and path
file_path = os.path.join(folder, filename)
with open(file_path, 'wb') as file:
file.write(response.content)
print(f"Downloaded sitemap: {filename}")
#Download whatever you find.
for maps in try_common_sitemap_urls('https://freshprinceofstandarderror.com', headers):
download_sitemap(maps, headers, download_folder)They are all in the folder we picked at the start. Cool.
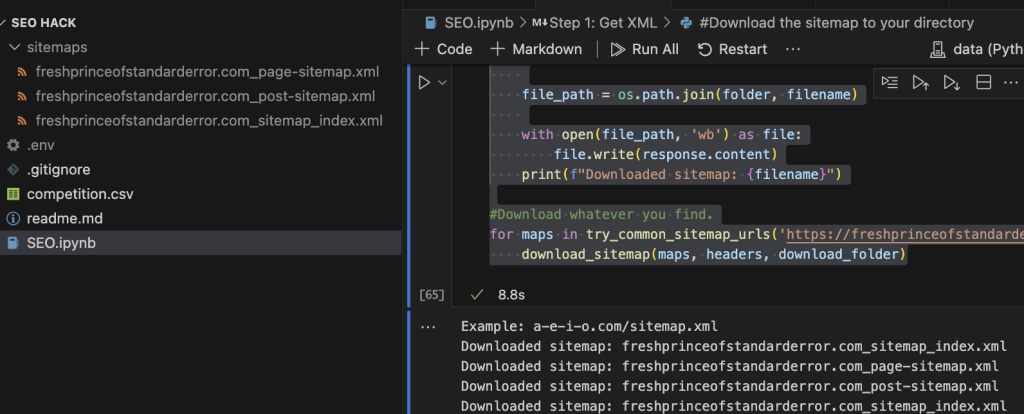
Parse the XML files to get all the URLs
Now we have the XML files, but we really want the article URLs from inside them.
from lxml import etree
def extract_urls_from_sitemap(file_path):
"""Extracts <loc> URLs from a sitemap XML file."""
with open(file_path, 'rb') as f:
tree = etree.parse(f)
# Define the namespace map to use with XPath
ns_map = {'ns': 'http://www.sitemaps.org/schemas/sitemap/0.9'}
# Find all <loc> elements in the XML file
loc_elements = tree.xpath('//ns:url/ns:loc', namespaces=ns_map)
urls = []
for loc in loc_elements:
# Extract the text content within CDATA
url = loc.text
urls.append(url)
return urls
# Call the function and print the results
urls = extract_urls_from_sitemap('sitemaps/freshprinceofstandarderror.com_post-sitemap.xml')
for url in urls:
print(url)My article links in all their glory. It’s getting kind of scary.
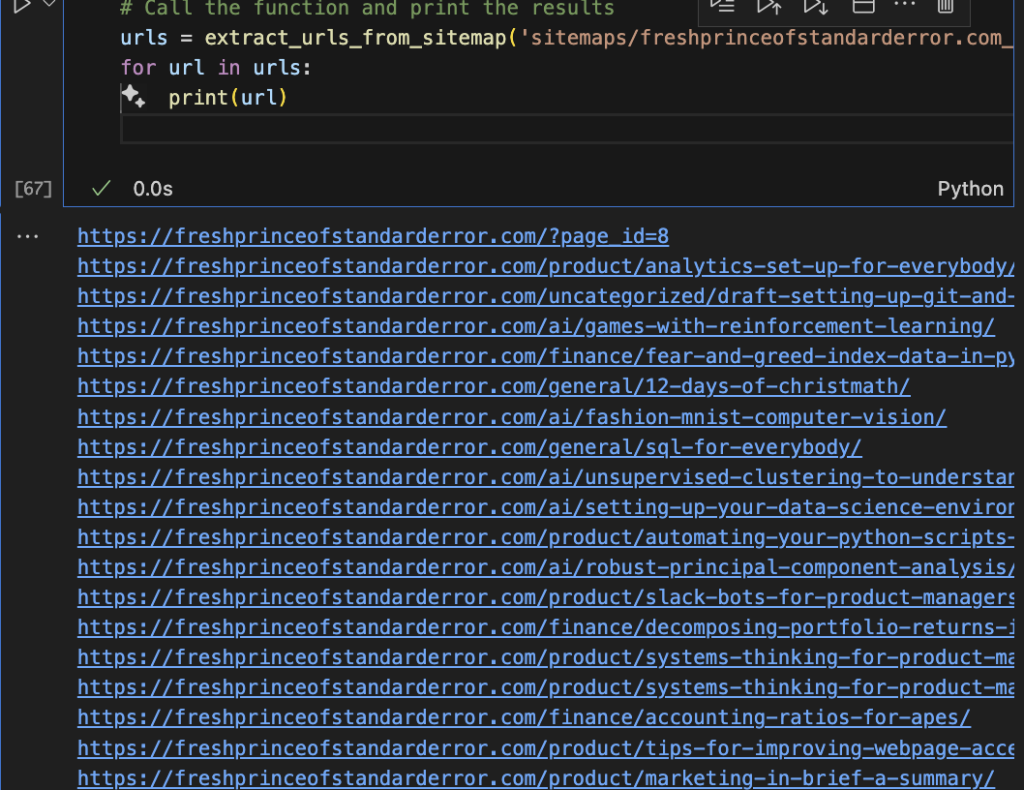
Title vs Article to get the content
Ok, so we are at an ethical dilemma. We can either use the URLs or scrape the entire article to generate new articles of our own.
Sometimes the links are not self-explanatory. For example website.com/how-to-do-something is a good URL. Other times links can be like website.com/sfdfsdjfjkhsd which is useless.
I guess let us scrape it to improve the quality of AI generated articles.
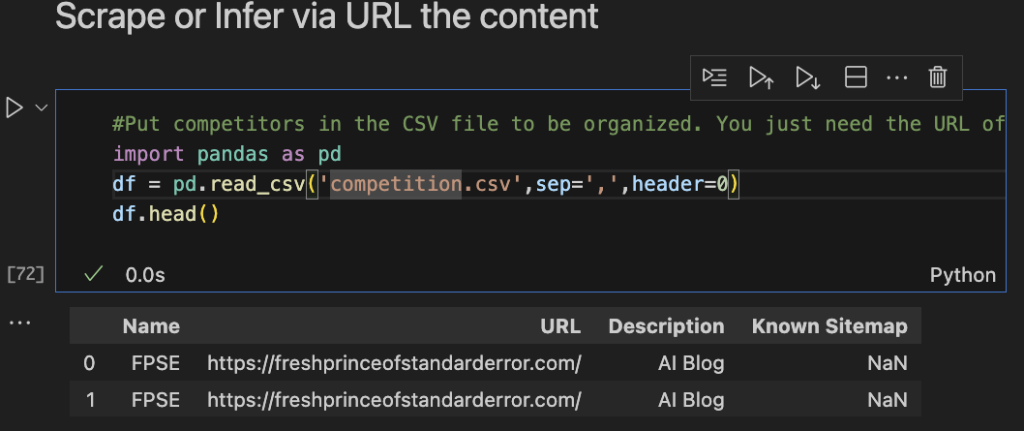
We can be kind of organized. Make a competition.csv file and put all your competition in there. Just make a list in the python file itself if you’re lazy.
#Put competitors in the CSV file to be organized. You just need the URL of their website.
import pandas as pd
df = pd.read_csv('competition.csv',sep=',',header=0)
df.head()I only put myself (twice) because I am my only competitor.
You can bulk download all your competitors as shown below. We did it earlier but not at such a large scale.
dem_urls = []
#Drop duplicates incase you have any and go through all the functions
for url in df['URL'].drop_duplicates().to_list():
for xmaps in try_common_sitemap_urls(url, headers):
download_sitemap(xmaps, headers, download_folder)
sitemap_files = [f for f in os.listdir(download_folder) if f.endswith('.xml')]
for file in sitemap_files:
urls = extract_urls_from_sitemap(f'{download_folder}/{file}')
for url in urls:
dem_urls.append(url)Let’s scrape em. We use BeautifulSoup like always. In my code below I handpicked only a few articles because I don’t want all of my own website.
# Cleaning the URLs by stripping whitespace
clean_urls = [url.strip() for url in dem_urls]
#Scrape or not to scrape?
from bs4 import BeautifulSoup
def scrape_title_and_text(url):
try:
# Fetch the content from url
response = requests.get(url)
response.raise_for_status() # Raises an HTTPError if the response status code is 4XX or 5XX
soup = BeautifulSoup(response.content, 'html.parser')
# Extract title
title = soup.title.text if soup.title else 'No Title Found'
# Extract all text
texts = soup.get_text(separator=' ', strip=True)
return title, texts
except requests.RequestException as e:
print(f"Error fetching {url}: {e}")
return 'Error', 'Error'
## Lets hand pick a few links, you can do as many, dont be a prick though.
articles_scraped = []
for url in clean_urls[1:3]:
title, all_text = scrape_title_and_text(url)
articles_scraped.append({'URL': url, 'Title': title, 'Text': all_text})
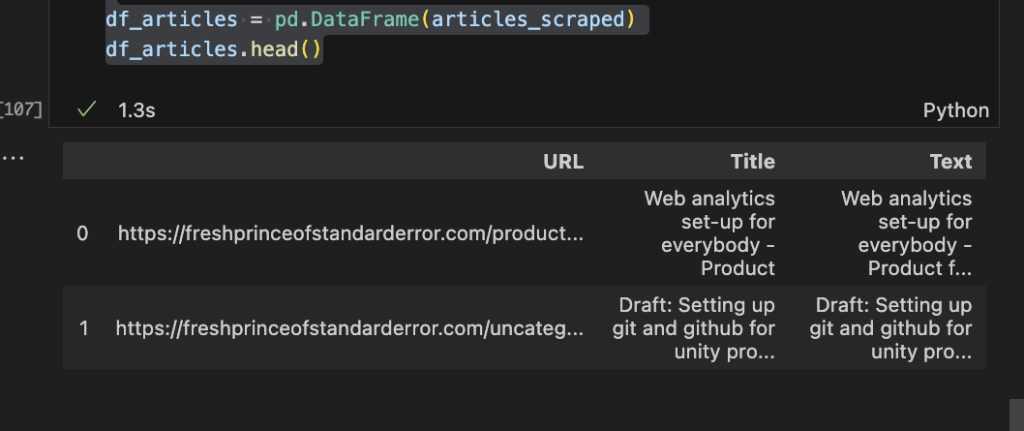
df_articles = pd.DataFrame(articles_scraped)
df_articles.head()Dataframe should look like this: URL, Title, Text.
AI generation of words and imagery.
We can use any model, including open source ones. Popular paid ones for text are OpenAI’s GPT and recently Anthropic’s Claude 3. Image ones are Midjourney and Dall-E.
OpenAI has a simple API for image and text so we’ll use that. You’ll need an API key.
Generating text is as easy as this.
from openai import OpenAI
from dotenv import load_dotenv #optional, just use your key
load_dotenv()
client = OpenAI(api_key=os.getenv('OAI_API_KEY'))
prooomp = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
#You can use GPT 4 if you're loaded "gpt-4-0125-preview"
def get_article(prompt,model="gpt-3.5-turbo"):
completion = client.chat.completions.create(
model=model,
messages=prompt,
temperature=0.7,
seed=0)
return completion.choices[0].message.content
get_article(prooomp)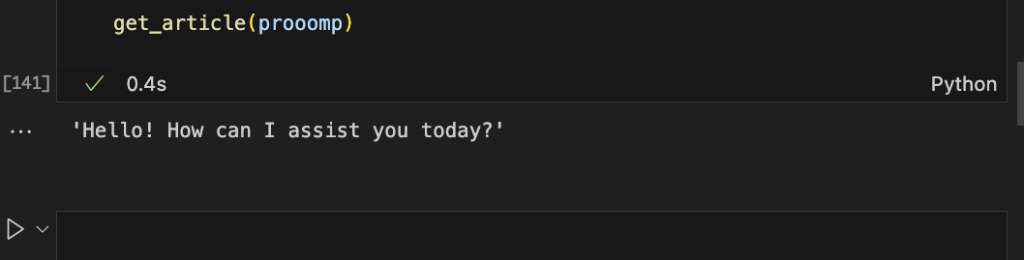
Prompt Engineering
Many people that work on ‘AI’ really use existing models and write their own prompt. I have forgotten all the models I have implemented from scratch, it’s more than most people. In this case since the models are so large, resource intensive to train, need a lot of training data etc. it makes sense to use an API rather than create or replicate it locally. Many companies, even somewhat popular ones like perplexity.ai are wrappers around OpenAI’s GPT. We too will wrap the crap out of GPT.
A prompt (in this case) has roles like system and user along with content. System is used only once at the start, often to give your model a personality and define tasks. Whatever people input afterwards is the role ‘user’ and when the model replies back it is the role ‘assistant’.
You can do cool things like define a personality for the model such as a Goth cheerleader.
personality = 'Goth cheerleader that is really into tech and darkness with a lot of personality. Use a lot of goth lingo.'
You can f string the personality into the regular prompt format. You can even have many personalities that get randomly sampled so your articles look like they have been written by different people. Oh we also need to put the entire article in the prompt. We’ll tell the model to use the article and generate a new similar one with whatever personality.
#Create a half baked prompt that puts in the article
personality = 'Goth cheerleader that is really into tech and darkness with a lot of personality. Use a lot of goth lingo.'
article_prompt = [
{"role": "system", "content": f"You are a SEO content writer and {personality}. You have this draft that you will edit and make it sound better for your cool blog. Also make it concise and to the point. Return back markdown format and remove all hyperlinks."},
{"role": "user", "content": f"Article:{df_articles['Text'][0]}"}
]
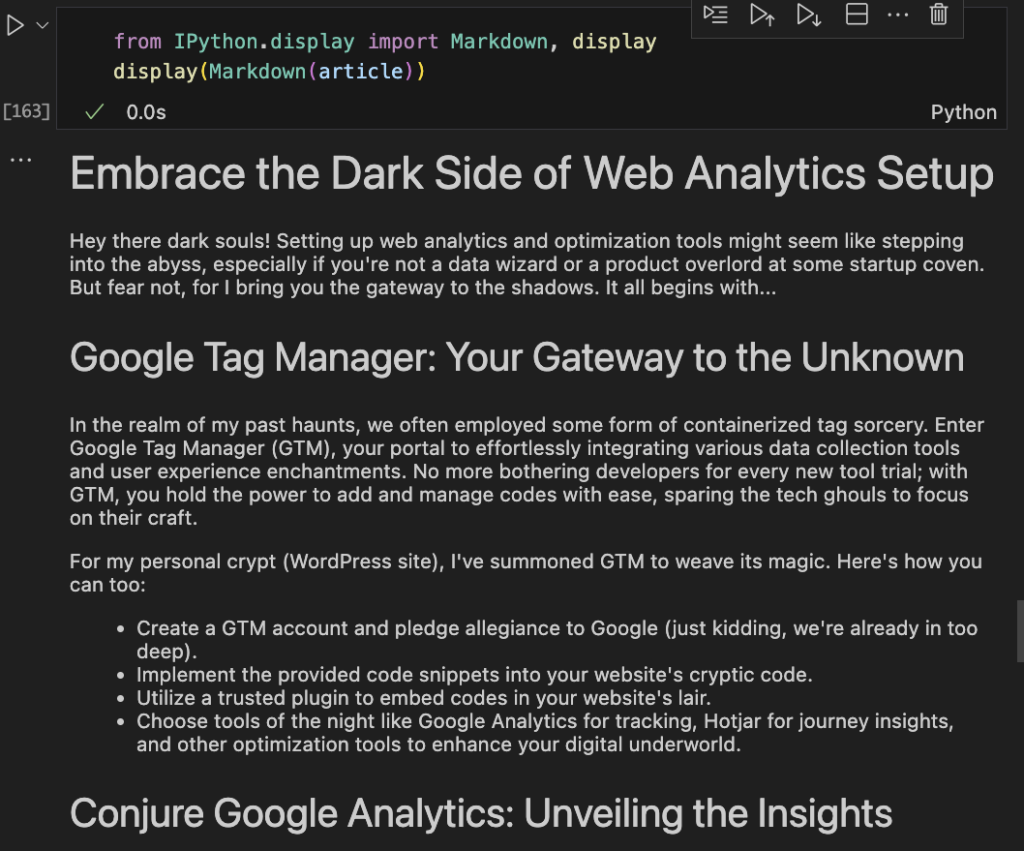
article = get_article(article_prompt)Display the article for your own viewing pleasure.
from IPython.display import Markdown, display display(Markdown(article))
Shit, this is too good. It’s scary good.
Generate a cover image with Dall-E and automatically upload a few articles to your CMS.
from IPython.display import Image, display # Generate a cover image using the first few words of the article response = client.images.generate( model="dall-e-3", prompt=article[0:100], size="1024x1024", quality="standard", n=1, ) image_url = response.data[0].url display(Image(url=image_url))

Upload thousands of articles to your CMS
Wait.. This is too powerful and dangerous. I can’t show any more. You can sabotage websites, make money from clicks, take over thousands of copywriting jobs and be a big prick. Think that is far-fetched? This article is actually to raise awareness of what people are already doing and what is possible.
References: