
Hai
I use NLP a lot, whether it has been to analyse customer survey data or to get insights from news articles and social media posts to find stock picks or create financial models. Using NLP for work can be as hard or as easy as you’d like it to be.
To follow along you’d need some competency in writing code. If you don’t have a Python environment then set one up quickly from here:
https://freshprinceofstandarderror.com/ai/setting-up-your-data-science-environment/
NLP for practitioners!
Transformers have become state-of-the-art modern architectures to achieve NLP that surpasses a lot of other deep learning architectures. It has many uses from sentiment analysis, speech recognition to auto-completion.
While models are “democratised” data is usually concentrated to big tech and so is the ability to have it properly formatted and labelled for many deep learning tasks. Thankfully Google’s open release of BERT (Bidirectional Encoder Representations from Transformers) trained on terabytes of data with 340 million parameters has made NLP accessible to many.
Hugging Face has been on a mission to provide exceptional api for pre-trained models that people can use without many hours of computation. Practical for many people from start-ups to large organisations.
Some background on newer models
Before we move to transformers maybe a little background would help. This is for people to have an okay foundation to look up some of those topics and their evolution. The math behind all of which is simple with some experience in linear algebra. The intuition is important and knowing their use-cases. I’ll add some resources at the bottom to help.
Words are correlated with one another and seeing something as simple as a word cloud using counts shows that we can find associations. Projecting them as vectors onto a Euclidian space can help find clusters or visualising it in branches by some metric can make you an interpretable tree. This sequential structure of words and their associations has been modelled with all sorts of algorithms such as Bayesian networks, Support Vector Machines and Artificial Neural Networks.
Deep learning models for NLP
If you’re unaware what Recurrent Neural Networks are then it helps to know they are a neural network architecture that does well at analysing sequential data. Kind of like words, or even time-series data. You need some information to persist, you have to transfer information about a word as an input to the next part of the process. However, there is a known problem of long-term dependencies and not being able to train a model in parallel because the next part of the process needs the previous one to give it an input.
If you want to autocomplete ‘I like oranges, it is one of the finer fruits and it makes me want a glass of its _____’ then the challenge becomes hard because of long-term dependencies! This is because of the nature of RNNs and how it transforms information without a lot of consideration for what is important.
There is another group of RNN architecture known as Long-Short Term Memory (LSTM). In each iteration the model makes small additions to each part of the sequence changing its importance. In this way LSTM can ignore things that are not so important to alleviate the long-term dependency problem.
A lot of improvements can be made using a mechanic called attention when dealing with longer-term dependencies. Attention is a way to model the second instance ‘..,it makes me want a glass of its _____’ and guess what ‘it’ is being referred to in that sentence. If you remember how you can measure the cosine similarity, take dot products and use the SoftMax function then comprehending the seminal paper in the reference section will be achievable and it is worth doing.
Anyway, because of the nature of RNNs computing in parallel is not possible. This produces a lot of greenhouse gases and computation complexity. Transformers are a type of architecture that make use of attention but also allow parallel computing. They used to have limitations such as needing to deal with a fixed-length of strings because they consider a sentence as a vector to help with parallel processing. However, in recent times people have overcome that challenge like in the model we will be using next.
Finally, practical transformers with hugging face
Hi again, regardless of whether you skipped the previous sections welcome to the practical portion.
To get some of that sweet NLP we need to install the following packages via anaconda prompt.
conda create -n nlp python=3.8
conda activate nlp
conda install -c anaconda tensorflow
conda install -c huggingface transformersThis creates a new environment called nlp running on python 3.8 and installs TensorFlow and the hugging face transformers library. We need python 3.8 because it is the highest supported version for TensorFlow (June 2021).
If you need help having the environment show up properly in Jupyter Lab follow the steps here:
https://freshprinceofstandarderror.com/ai/setting-up-your-data-science-environment/
you likely just need these two commands in your nlp environment to make it show up properly
conda install ipykernel
python -m ipykernel install --user --name=nlpAnyway, once you have Jupyter open click on the correct environment to make a notebook.

Name the notebook something stupid and run this code
from transformers import pipeline
sent_model = pipeline('sentiment-analysis')
Now for the fun part, testing it out
words = ['Awal is funny',
'Awal is not funny',
'Awal is a sweet baby boy',
'Awal is a turd']
[sent_model(x) for x in words]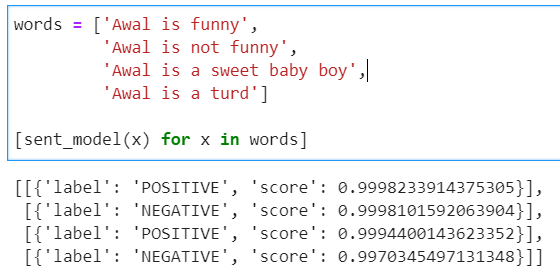
WOW much simple, so quick. You can see that it provides a label and an accuracy score. If you provide it a challenging sentence that is sarcastic or ambiguous then it will have a lower accuracy score.
Model building with a use case
Now we’ll do something I have had to do often and build a simple model while analysing some real Airbnb data found on this link:
http://insideairbnb.com/get-the-data.html
This will give you practical experience and allow using this powerful tool at work. I picked the data for Amsterdam, choose the reviews.csv.gz file so you get all the text reviews and extract the reviews.csv file and put it in the same folder as your notebook.
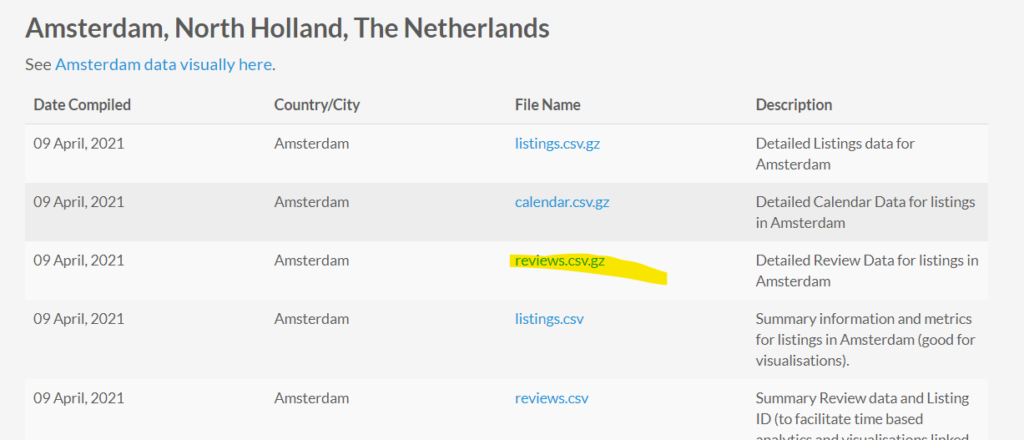
It should look something like this after you load it with the following commands:
import pandas as pd
df = pd.read_csv('reviews.csv')
df.head()Pandas was installed as a dependency earlier, it is a nice numerical computation package that stores numpy arrays as a dataframe, which are like excel tables.
Don’t be alarmed that my screenshot is in black. It’s because I use Visual Studio Code. I’m more productive in it but recommended Jupyter Labs for beginners which does the same thing.
We want to use the comments column and apply our sentiment model to each of the rows. However, first we want to make sure the reviews are of type string, because that is the input type required by the classifier. We can check all the data types by running this
df.dtypes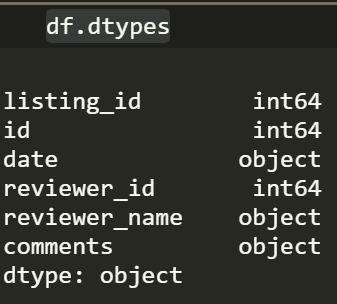
You probably see an issue that comes up very often. Data is not the right format, we could have imported it correctly by specifying what datatype each column was but then you would miss out on all the fun.
You need to convert the comments into string type. To be safe limit the comments to first 500 characters.
df['comments'] = df['comments'].astype(str).str.slice(0,500)If you’re a developer you probably want to write a loop or some kind of recursive function to apply the classifier but use this instead. It probably inexplicitly uses a loop but pandas and numpy are performant because they pass a lot of computationally expensive tasks to C(ish) via cython or whatever else.
df = df.tail(50) #Use this if you work on a potato
df['sentiment'] = df['comments'].apply(sent_model)
display(df)The code above limits the dataframe to the last 50 rows to help those people that have an old or slow computer. I can run it on everything but I ran it on the last 2000 rows. It can take a while otherwise since there are 426k rows.
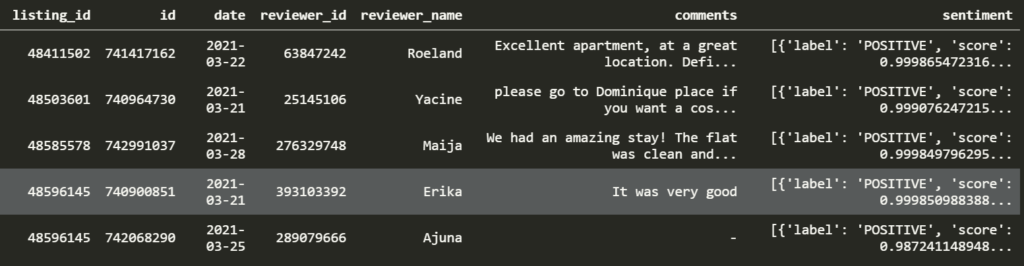
The sentiment column is a mess with each row containing a list that has a nested dictionary in it. I left it this way so I can show you how to split it into columns.
It is tricksy because it requires converting each row to a series and grabbing the dictionary in it. Then if you have worked with dictionaries before you can apply pd.Series again to convert it into two separate columns ✌. This comes with painful experience so be glad you did not have to learn it the hard way.
sentiment_df = df['sentiment'].apply(pd.Series)[0].apply(pd.Series)
sentiment_df['encoded'] = sentiment_df.label.replace({'NEGATIVE':-1,'POSITIVE':1})
sentiment_df[['date','comments']] = df[['date','comments']]
display(sentiment_df)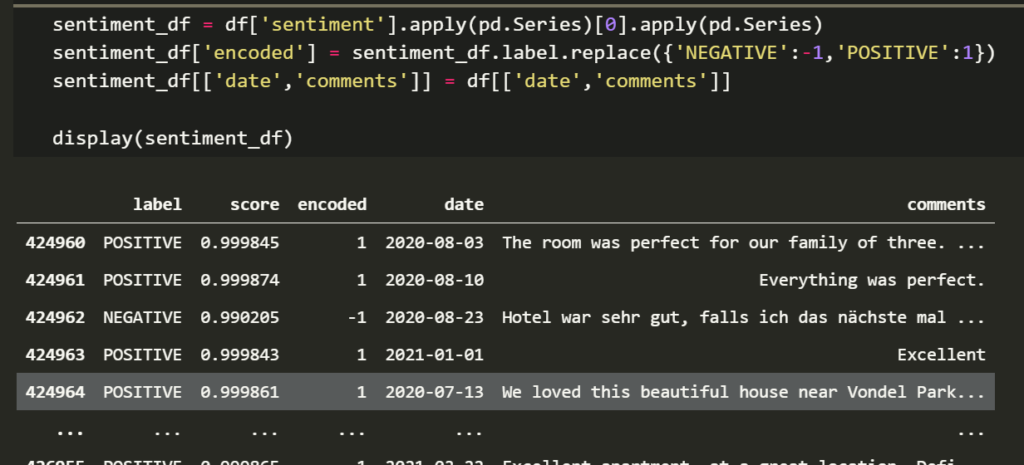
The second line above will encode the positive categorical variables as 1 and negative as -1. This is cool because it’ll make the simple model we spoke about earlier.
If we multiply the columns for score * encoded then you will get back an accuracy weighted value that takes into account accuracy and the sentiment. If something is negative (-1) but not too accurate (.4) then it gets a lower score (-1*.4 = -.4). This can be averaged across a bunch of rows to get a periodic value like this
sentiment_df['date'] = pd.to_datetime(sentiment_df['date'])
sentiment_df.index = sentiment_df['date']
sentiment_df['model_score'] = sentiment_df['score'] * sentiment_df['encoded']
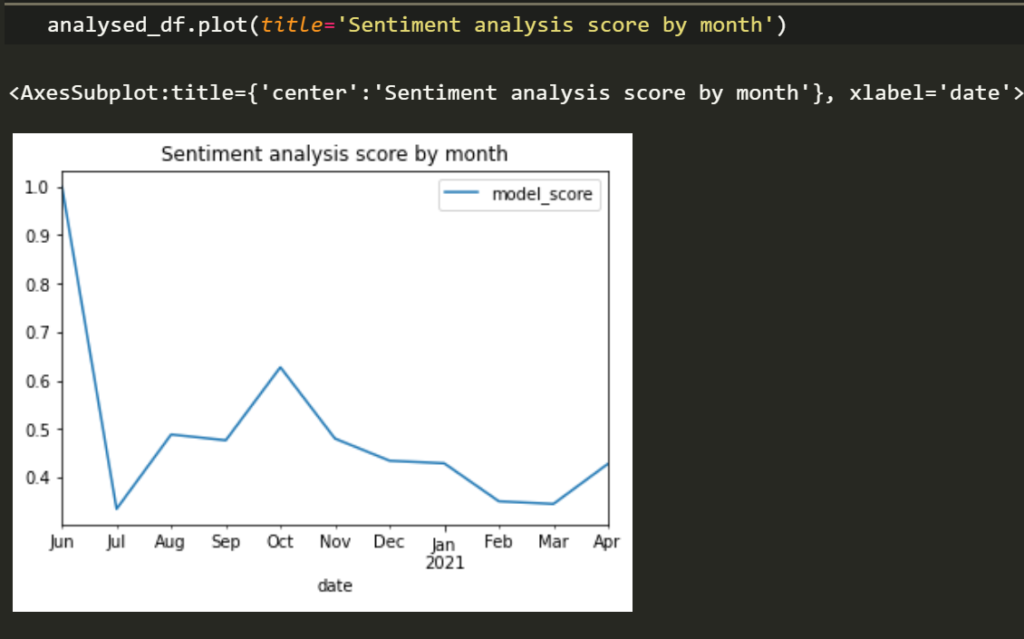
sentiment_df[['model_score']].resample('M').mean()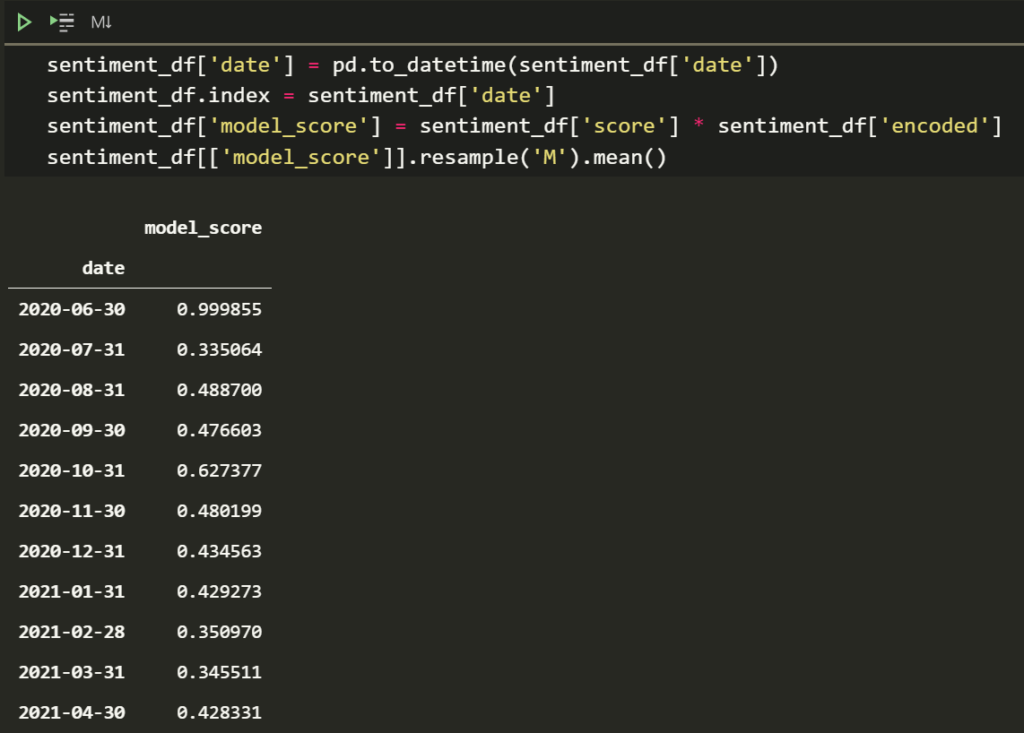
As you can see our model is okay. Interestingly if you have picked a period before the pandemic you’d see a lot of positive reviews (I tried). If the data is missing for some of the months in whatever dataset you picked instead of Amsterdam then we will have to make a tough decision about whether to ignore the missing data or use some kind of interpolation.
In this instance we’ll replace missing values with the mean as an example. For practical purposes if you are using machine learning with a train and test split then you want to do the splitting first before the interpolation. Otherwise you’ll be peaking into the test set via the mean.
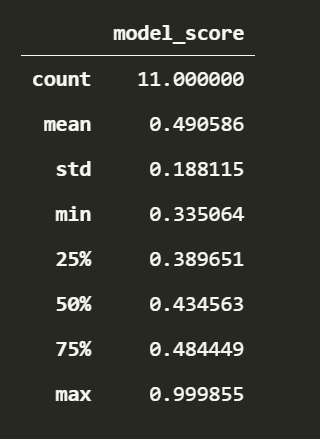
analysed_df = sentiment_df[['model_score']].resample('M').mean()
analysed_df.fillna(analysed_df.mean())
analysed_df.describe()You’ve now finished the hard but still easy NLP for sentiment analysis
Now we can plot it if you like. I usually present my data in visualisations but you don’t have to; it really depends on where you work. You can tell people in Amsterdam are not particularly happy as of late.
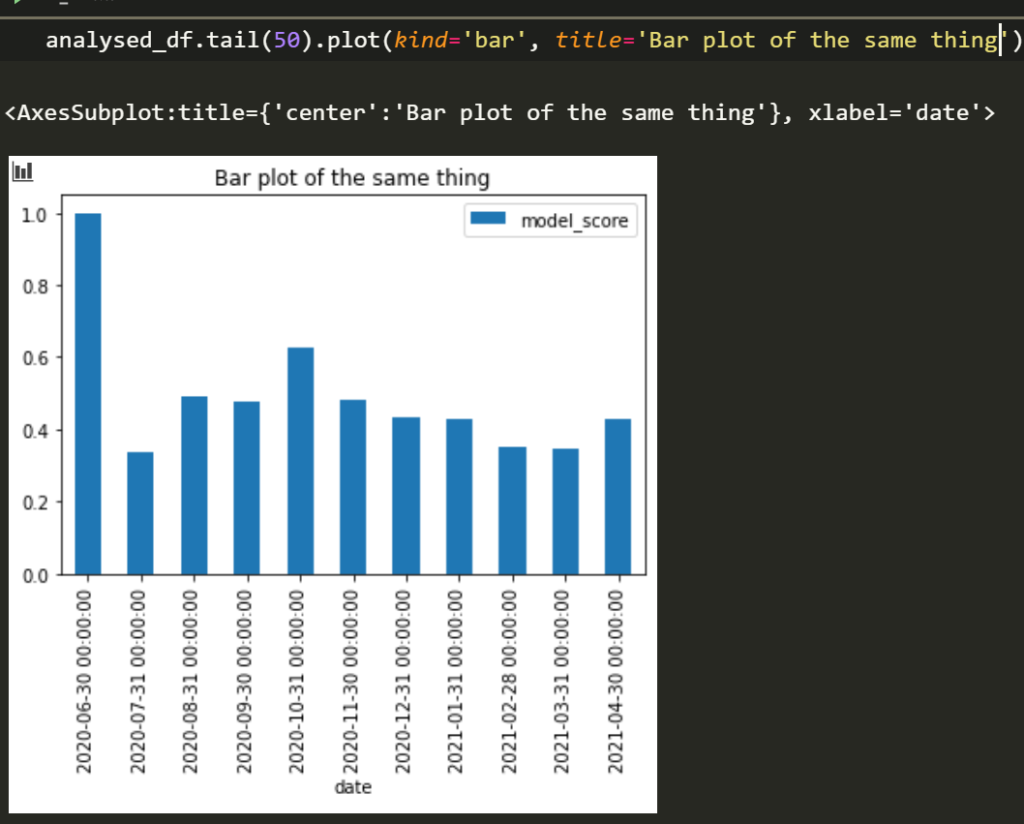
Summary of what you learned
- Installing new libraries via conda
- Using an environment
- Loading a dataset into Jupyter Labs
- Converting datatypes
- Using sentiment analysis on comments
- Splitting messy sentiment data into columns
- Creating a model that gives you a better sentiment score
- Creating simple diagrams to showcase your data
What you should try
- Using a pre-pandemic period to analyse sentiment
- Some other model available via hugging face
- Reading the articles in useful reads
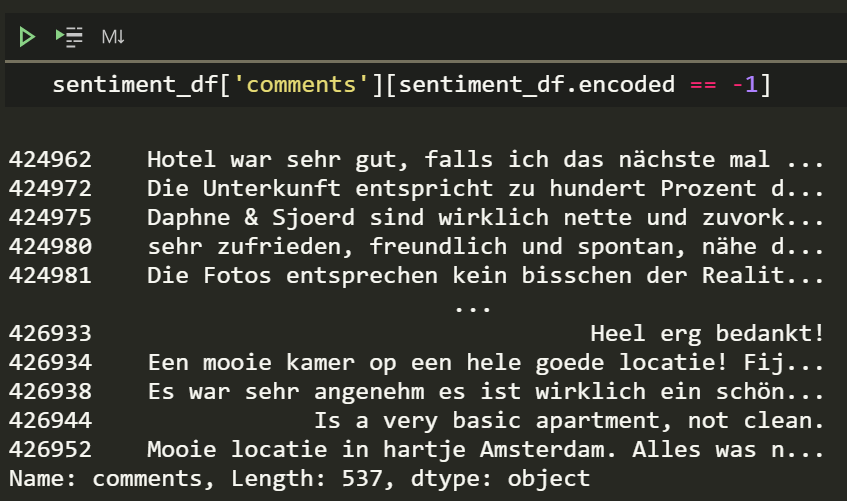
Negative comments for lols
Did I mention you can find the sentiment from a range of languages Thank you Google.
Useful reads
https://distill.pub/2019/memorization-in-rnns/
https://arxiv.org/abs/1706.03762 – Attention is all you need paper
https://blog.google/products/search/search-language-understanding-bert/
https://huggingface.co/transformers/installation.html
Maybe Andrew Ng’s Sequence Models course on Coursera.